音声認識のキーワードにマジック・ザ・ギャザリングのカード情報が含まれた場合、カードのイラストを引き当てて表示します。
事前設定

ゆかりねっとコネクターNeoのプラグインを有効に(チェックをONに)します。
引き当てるデータ設定
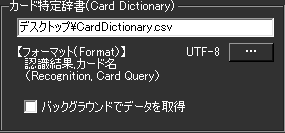
まず、辞書ファイルをつくって読み込ませます。これは「どのキーワードがきたら、どのカードを検索するか」を定義するものです。
検索キーワードは「https://magicthegathering.io/」に乗っているものが基準となります。

上記のような感じのファイルを作りましょう。
バックグラウンドでデータを取得にチェックを打つと、上記のカードデータやテキストデータをあらかじめサーバからダウンロードします。
サーバからデータをダウンロードするスピードは凡そ15枚/分程度です。サーバへ負荷をかけないように、ペースが少し落ちています。また、サーバが込み合っているときはダウンロードに失敗します。
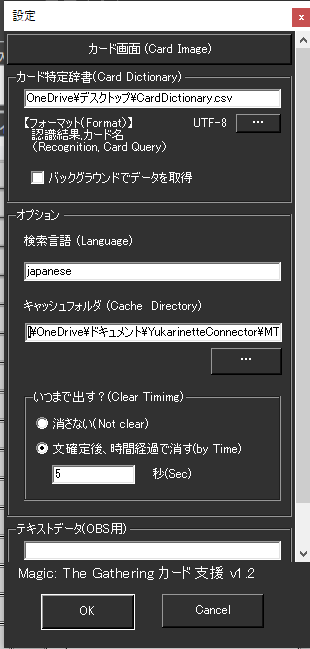
その後、上記も設定しましょう。
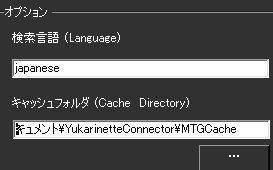
・検索言語は基本的に japanese でよいかと思います。もし海外ユーザが使う場合は、検索キーワードのファイルに書いた言語にあわせて言語名をいれてください。
・キャッシュフォルダも設定しておきます。検索エンジンは検索上限があるので何度もおなじようなものを検索してしまうと通信を止められてカード画像を得られなくなってしまいます。そのため、1度取得した映像をストックし、再利用します。
そのあと、

を押すことで、表示画面が出てきます。
自動解説アプリとの連携
@poslog さんが作成された解説ツールと連動することで、カードを出したり読み上げしたり字幕を出したりできます。
ツールは下記の場所にあります:https://github.com/poslogithub/binary-dist/blob/main/mtga-commentary-automation/README.md
ツールを起動すると、CardDictionary.csv というファイルが生成されます。カード特定辞書として使えます。
1つポイントがあって、たとえば音声認識で使いたい場合は「《大渦のきずな》の紋章」の「《」などが一致しないために、カードがちゃんとでないことがあります。
その場合は、
手段1:置換辞書で「《大渦のきずな》の紋章」と置き換える
手段2:カード辞書に「大渦のきずなの紋章」を追加
みたいな形で、表示するように動作精度を高めることができます。
カードデータの表示
- カードデータを取り込むためには、OBSなどでウィンドウをキャプチャーする設定をして下さい。
- カードテキストデータをOBSに取り込むことができます。
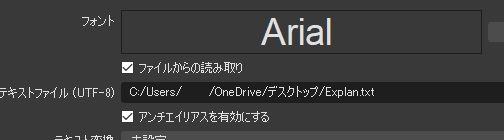
- ファイルはカード認識したときに生成されます。
- ファイル名は、Explan.txt、Flavor.txt、name.txt、type.txtの4つです。
- OBSのソースでファイルを読み込むことで、画面に取り込むことができます。
- ファイルを作る位置はここで指定します。